
There’s this guy Jeff Preshing who has this blog which I like. He doesn’t update very often but his articles are interesting and well written. I was thinking about how one might use C++11 atomics to update some code he wrote in 2012 to explore memory re-ordering / ephemeral cache incoherence. My efforts resulted in the following which illustrates the ‘Store then Load’ instruction reordering that x86 architecture allows. In this post I’m going to further discuss the methods that Jeff suggests and conclude with an analysis of my code and how modern C++ solves the problem of CPU reordering.
The most significant difference from Jeff’s code is that I don’t use a semaphore for signaling and synchronization, instead I use a C++11 atomic boolean with memory_order_release to make sure it’s the last thing that’s executed in each of the thread functions. This leaves us able to play around with the important parts of the code which I see as the shared types we’re using.
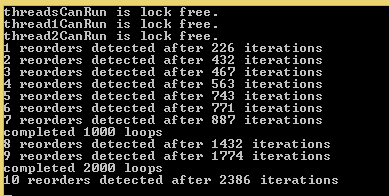
Let’s make sure the code I’ve written does what Jeff’s code does before we get too far ahead of ourselves. It looks like we’re getting the same reordering Jeff observed, although I’m surprised we’re getting it so much more often than he did.
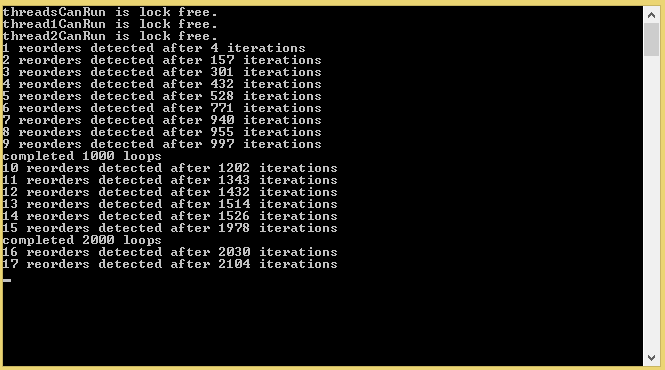
Single Core
Just like in Jeff’s example, we can eliminate the reordering by binding both threads to a single core (neat but not necessarily practical). Placing this code right after the thread instantiations does the trick (adding the Windows.h header is necessary).
...
std::thread t1(ThreadFunc1);
std::thread t2(ThreadFunc2);
SetThreadAffinityMask(t1.native_handle(), 1);
SetThreadAffinityMask(t2.native_handle(), 1);
while(true)
{
...
As expected, no reordering.
Mutex
We get the same result if we lock a global mutex right after the sleep operation.
...
if(threadsCanRun & thread2CanRun){
std::this_thread::sleep_for(std::chrono::milliseconds(rand()%100));
std::lock_guard<std::mutex> lock(mutex);
thread2HasRun = true;
...
But that’s not sporting! This is about writing lock-free, gluten-free, free-range, non-GMO, vegan, kosher code. Jeff uses _ReadWriteBarrier(), MemoryBarrier(), and MFENCE to keep the code from shuffling, so let’s take a look at those. If you are interested in seeing the disassembly for this follow this.
Compiler Reordering and MS _ReadWriteBarrier()
_ReadWriteBarrier() keeps the compiler from reordering the operations. This is very important if we want to make sure that whatever reorderings are actually happening are in the CPU. Although _ReadWriteBarrier() is depreciated, the MSVC (version 18.00.xxx) compiled it happily and we can see the correct ordering in the first 3 lines of the disassembly.
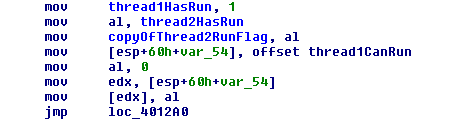
Just for comparison’s sake, here’s the disassembly of the same code without the _ReadWriteBarrier(). This is what the base code compiles to before we try to convey anything about memory ordering to the compiler or CPU.
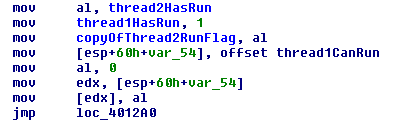
Interesting, without the barrier we load the thread2HasRun before we write to the variables, which has the effect of switching the order of the lines I wrote!
//what I wrote ... thread1HasRun = true; copyOfThread2RunFlag = thread2HasRun; ... //what the compiler did ... auto temp = thread2HasRun; thread1HasRun = true; copyOfThread2RunFlag = temp; ...
If there was no CPU reordering in play, we might expect that the _ReadWriteBarrier() would solve our reordering worries. Here’s the console output from this program and we are still seeing the reordering! This tells us that what we’re detecting is not just a matter of the machine code being ordered correctly, but an issue with cache coherence.
Volatile
If we declare the bools thread1HasRun, thread2HasRun, copyOfThread2RunFlag, copyOfThread1RunFlag as volatile we get the same the compiler ordering as using _ReadWriteBarrier(), and just like in that case, our CPU reordering issue is not resolved.
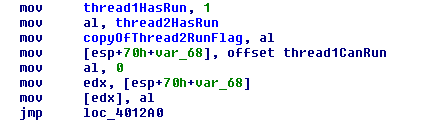
This is because volatile conveys that a memory location can be updated from multiple places (like an interrupt or some other device or just another core) and the compiler can’t make any assumptions about how it will change. Since the compiler sees the code writing a constant to a volatile and then writing to a volatile from a volatile, it is obligated to follow the order as written and not cache the value of thread2HasRun. If we remove the volatile keyword from thread1HasRun and thread2HasRun then we get the same reordering we saw in the naive, compiler-reordering code that we disassembled earlier. Volatile is an interesting keyword and worth reading something and a bit more about if you’re curious.
MemoryBarrier()
The MemoryBarrier() function should solve our problem since it prevents both compiler reordering and CPU reordering. We place it within our thread method like so
... thread1HasRun = true; MemoryBarrier(); copyOfThread2RunFlag = thread2HasRun; ...
From this we get the following disassembly.
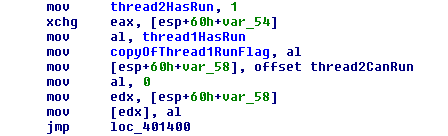
Firstly, we are getting the order as we wrote it, just like when we used _MemoryReadWrite(), but we’ve also gotten an xchg operation. XCHG performs a bus lock whenever it accesses memory (which is what is happening within those square brackets) which means that other cores can’t access that memory location (cache coherency may allow other memory locations to still be accessible). In volume 3A of the Intel 64 and IA-32 Architectures Software Deeloper’s Manual, section 8.1.2 reads, “For the P6 family processors, locked operations serialize all outstanding load and store operations (that is, wait for them to complete).” That solves our CPU reordering issue because instructions can’t be rearranged over a locked instruction.
x86 CPU Fence Instructions
Another solution is to use some assembly and force the hardware to serialize instructions using SFENCE (for store to memory only), LFENCE (for load from memory only), or MFENCE (load and store). These are x86 specific and naturally don’t have standard C++ support, so I’m only going to briefly touch on this. We can create a memory fence using the _mm_mfence() method like in the following
... thread1HasRun = true; _mm_mfence(); copyOfThread2RunFlag = thread2HasRun; ...
The disassembly looks like this, not only do we have instruction order from the compiler in the same order as we coded but there is a mfence instruction.
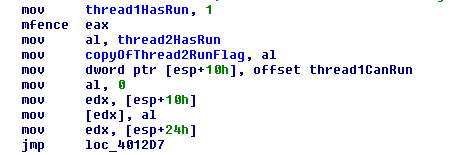
This solves the CPU reordering problem for us just as we might expect.
C++11 Store
We’re going to declare our variables as std::atomic<bool> and use the Store method to write to the ‘copy’ variables. The store method takes a memory order type and there are really only two that make sense here, memory_order_release or memory_order_relaxed. Relaxed allows reordering but requires the store be atomic. Release is also atomic but no memory accesses that happen before this operation can be re-ordered to be after it. This means that the thread1HasRun = true; statement can’t be moved to after writing the thread2HasRun variable into the copy variable.
Here’s ThreadFunc1 as you see it in the code that can be downloaded above, ThreadFunc2 is the same but all the 1s are 2s and the 2s are 1s.
...
std::atomic<bool> thread1HasRun, thread2HasRun, copyOfThread2RunFlag, copyOfThread1RunFlag;
...
void ThreadFunc1(){
while(true) {
if(threadsCanRun && thread1CanRun) {
std::this_thread::sleep_for(std::chrono::milliseconds(rand()%100));
thread1HasRun = true;
copyOfThread2RunFlag.store(thread2HasRun, std::memory_order_release);
thread1CanRun.store(false, std::memory_order_release);//nothing can be reordered past this operation
}
}
};
...
Upon looking at the disassembly, I saw that the compiler put loading the memory address of thread1HasRun before the random sleep instructions, and since that random sleep step is a can of worms I’m just going to show you the important memory load that got moved.
![]()
The edi register now has the location of the thread1HasRun variable which is then atomically exchanged with the value 1 on the second line of the following disassembly (this picks up right after the random sleep).
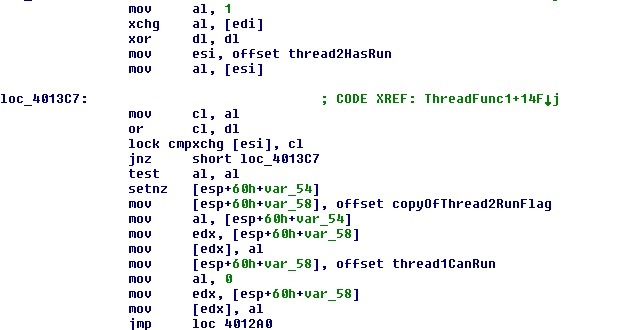
There is a lot going on here so we’ll walk through it slowly. First the xor clears the contents of dl so that we can use it later. The following mov then stores the memory location of thread2HasRun into the esi register, we’ll use this memory location later to get exclusive access to thread2HasRun. Then the value of thread2HasRun gets copied to the al and cl registers. We’ll want these copies later. Strangely, since the dl register is 0 from the xor earlier, the ‘or’ operation doesn’t do anything.
Next we do a locking cmpxchg which checks to make sure that the contents of esi and cl are the same. If the values aren’t the same then some other thread has changed the value of thread2HasRun between copying it into cl and running the cmpxchg so we loop back to loc_4013C7 using the the jump-if-not-zero (jnz) instruction. We know that exchanges create a bus lock that restricts memory access to the memory located variable, which in this case is the memory location in esi, thread2HasRun. So basically we see a loop until we have an exclusive lock on thread2HasRun.
The test and setnz operations just check if thread2HasRun is 0 or 1 and stores that in the temp memory variable [esp+60h+var_54]. Likewise, the memory location of copyOfThread2RunFlag is stored in the temp variable [esp+60h+var_58], which gets moved to the edx register. The mov [edx], al step is where the value of thread2HasRun gets placed in the memory location of copyOfThread2RunFlag.
Everything after that is the same thread1CanRun storage code that we’ve seen in all previous disassemblies.
C++11 Load
Another way of writing this code is via the Load command. Again we declare the variables as atomic bools but this time ThreadFunc1 looks like the following.
void ThreadFunc1(){
while(true){
if(threadsCanRun && thread1CanRun){
std::this_thread::sleep_for(std::chrono::milliseconds(rand()%100));
thread1HasRun.store(true,std::memory_order_release);
copyOfThread2RunFlag = thread2HasRun.load(std::memory_order_acquire);
thread1CanRun.store(false, std::memory_order_release);//nothing can be reordered past this operation
}
}
};
In this code we are publishing the update to thread1HasRun when we change its value and then we acquire that update before assigning to copyOfThread1RunFlag in the ThreadFunc2 which mirrors the above code (or see the download that I linked to at the top). Notice the memory_order_acquire in the above code, this indicates that before assigning to the copy, we make sure we are getting any changes that were published in other threads for this variable.
Like before, the code was compiled into two parts, one where the memory location of a variable is stored before the random sleep and then the assignments after the sleep. The pre-storage this time was for copyOfThread2RunFlag which is being raw assigned instead of set through the store property (recall that thread1HasRun was moved in the Store case when it was set via the equals sign).
![]()
We see thread1HasRun gets the value 1 stored to it in the instructions before the xor with no special precautions taken. We then get an exclusive lock on thread2HasRun, like we saw in the ‘Store’ code in the previous section, followed by an assignment to copyOfThread2RunFlag.

This is a little different than the Store example that was given before, but the basic pattern of creating a spin lock is the same with the cmpxchg and the jnz, it’s really just a matter of which variables are loaded and stored to on each side of the spin lock. This order can make all the difference though. For us, both the Store and Load examples I’ve explored provide adequate protection to keep memory from being reordered in unacceptable ways.
That’s all for this week, thanks for taking the time to read my ruminations.
Addendum
- All disassembly was of code compiled by MSVC with the optimization for speed enabled.
- Did you know that the volatile modifier is discarded for datatypes that are larger than what can be copied using a single instruction on the target architecture?
- The sections of code that create variability (the sleep code and the checking for reordering in the main thread) was removed and each version was run to 50 million iterations. The time to reach 50 million iterations was recorded and the results were divided into the solutions which prevented CPU reordering and those that didn’t. These numbers shouldn’t be taken too seriously since this was not a well controlled test.
Approaches With reordering Time (seconds) Unmodified (reordered) 37.281 _ReadWriteBarrier() 37.519 Volatile 37.891 Approach With Correct Ordering Time (seconds) Mutex 61.751 Core Binding 41.227 Atomics (store) 44.117 Atomics (load) 42.265 MemoryBarrier() 40.508 _mm_mfence() 39.569